Ihr Abonnement des Genesys-Blogs wurde bestätigt!
Please add genesys@email.genesys.com to your safe sender list to ensure you receive the weekly blog notifications.
Abonnieren Sie unseren kostenlosen Newsletter und erhalten Sie alle Updates zum Blog bequem in Ihre E-Mail-Inbox.
Diese Meldung nicht mehr anzeigen.

Als ein Schlüsselaspekt der künstlichen Intelligenz (KI) überbrückt Natural Language Understanding (NLU) die Lücke zwischen menschlicher Sprache und dem Verständnisvermögen von Computern. Bots, die natürliche Sprache verstehen, haben für Unternehmen mittlerweile große strategische Bedeutung in Bezug auf die Customer Experience. Das erste, was ein Bot verstehen muss, ist die Kundenabsicht. Wenn der Bot die Absicht richtig erkennt, macht er sich an die Lösung des Kundenproblems im Selfservice. Manchmal ist jedoch nicht ganz sicher, ob das NLU-System die richtige Absicht erkannt hat. In diesem Fall wird der Benutzer aufgefordert, die erkannte Absicht zu bestätigen – oder zu ändern. Betrachten wir nun die Verwendung von Konfidenzschwellenwerten und die Schwierigkeiten, die bei mangelndem Verständnis für ihre Auswirkungen auf die Wirksamkeit des Bot entstehen. Wenn ein NLU-Modell eine Hypothese für die Absicht hinter einer Äußerung aufstellt, gibt es dazu einen Konfidenzwert an. Schauen wir uns an, was dieser Wert bedeutet.
Wenn ein dialogorientiertes KI-System seiner Antwort einen Wert für „Konfidenz“ beimisst, ist dies im Sinne von „Vertrauen“ zu verstehen. Der Wert gibt an, wie hoch das Vertrauen des Systems in seine Hypothese ist. Der Wert mag wie ein Wahrscheinlichkeitswert aussehen, aber die Summe der Konfidenzwerte für einen Satz Hypothesen ist meistens nicht 1.
Verwechseln Sie den Begriff „Konfidenzwert“ nicht mit dem „Konfidenzintervall“, das in Statistiken zur Beschreibung der beobachteten Ergebnisse in einer Testreihe dient. In der Statistik ist ein Konfidenzintervall von 95 % der Bereich, in dem 95 % der Ergebniswerte liegen. Aber bei uns bedeutet Konfidenz etwas anderes. Ein Konfidenzwert kann auch mit der „Wahrscheinlichkeit“ verwechselt werden, dass eine Hypothese richtig ist, weil die meisten NLU-Engines Konfidenzwerte zwischen 0,0 und 1,0 ausgeben. Aber es geht hier auch nicht um Wahrscheinlichkeit.
Die Leistungsfähigkeit eines KI-Systems kann anhand seiner Leistung bei verschiedenen Konfidenzschwellenwerten charakterisiert werden. Bei einem Konfidenzschwellenwert von 0 würde es jede Hypothese zulassen, unabhängig von ihrer Richtigkeit und ihrem Konfidenzwert. Bei einem Wert von 1 würde es jede Hypothese ablehnen (es sei denn, die Engine gibt manchmal einen Konfidenzwert von 1 aus). Idealerweise sortiert ein Konfidenzschwellenwert so viele falsche Hypothesen wie möglich aus, ohne allzu viele richtige Hypothesen zu verwerfen. Eine Methode zur Ermittlung dieses Punktes besteht darin, eine ROC-Kurve (Receiver Operating Characteristic) zu zeichnen, die bei verschiedenen Konfidenzschwellenwerten die richtig positiven mit den falsch positiven Werten abgleicht, wie in dieser Abbildung dargestellt.
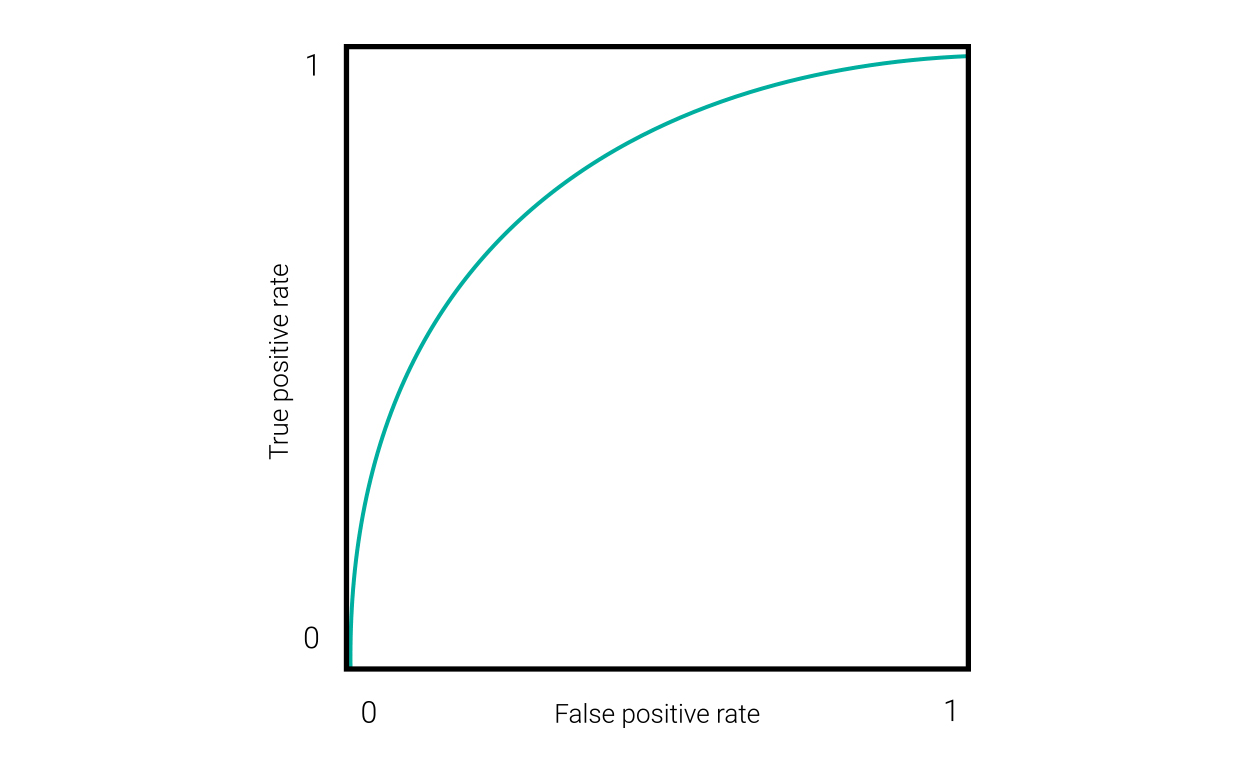
Am höchsten ist der Konfidenzschwellenwert in der unteren linken Ecke des Diagramms mit 0 richtig positiven und 0 falsch positiven Ergebnissen. Der niedrigste Schwellenwert liegt oben rechts. Der optimale Punkt mit der größtmöglichen Zahl an richtig positiven und der geringstmöglichen Zahl an falsch positiven Ergebnisse liegt zwischen ihnen. ROC-Kurven, wie die oben genannten, eignen sich gut für eine binäre Klassifizierung. Eine NLU-Engine, die die Absicht hinter einer Äußerung vorhersagt, ist jedoch ein System mit mehreren Klassen. Und damit nicht genug: Das System muss auch danach bewertet werden, wie gut es nicht der Domäne zugehörige Eingaben oder „wahre Negative“ verarbeitet. Um dies zu erfahren, müssen wir die Ergebnisse entsprechend der konkreten Art des Konfidenzschwellenwertes betrachten, die wir verwenden möchten.
Eine NLU-Engine kann bei der Übermittlung von Hypothesen zwei Arten von Konfidenzschwellenwerten angeben: Bestätigungsschwellenwert: Wenn der höchste Konfidenzwert einer Absichtshypothese unter diesem Wert liegt, bittet der Bot den Benutzer um Bestätigung der Hypothese. Ablehnungsschwellenwert: Wenn der Konfidenzwert unter diesem Wert liegt, fordert der Bot den Benutzer auf, die Eingabe zu ändern. Eine dritte Variante kommt dann ins Spiel, wenn die plausibelste Hypothese nur knapp vor der zweitplatzierten Hypothese liegt. In diesem Fall kann der Bot den Benutzer auffordern, zwischen den beiden zu wählen.
Um einen guten Schwellenwert für einen Bot zu finden, sollte ihm optimalerweise ein Satz von Testdaten mit empirisch wahren Werten übergeben werden. Anschließend werden die Ergebnisse bei unterschiedlich hohen Konfidenzschwellenwerten verglichen. Da der Bestätigungs- und der Ablehnungsschwellenwert unterschiedliche Zwecke haben, müssen sie separat bewertet werden.
Diese vier Hypothesenkategorien sind für einen Bestätigungsschwellenwert relevant:
Hinweis: Von diesen Hypothesengruppen ist 1 der beste Fall, 3 der schlechteste; 2 und 4 liegen dazwischen. Das liegt daran, dass es für den Benutzer zwar lästig sein mag, ständig um eine Bestätigung gebeten zu werden, dies aber immer noch besser ist, als wenn eine falsche Antwort akzeptiert wird. Das folgende Diagramm zeigt diese vier Werte für einen Beispieldatensatz in 0,1-Schritten von 0 bis 1,0 Konfidenz.
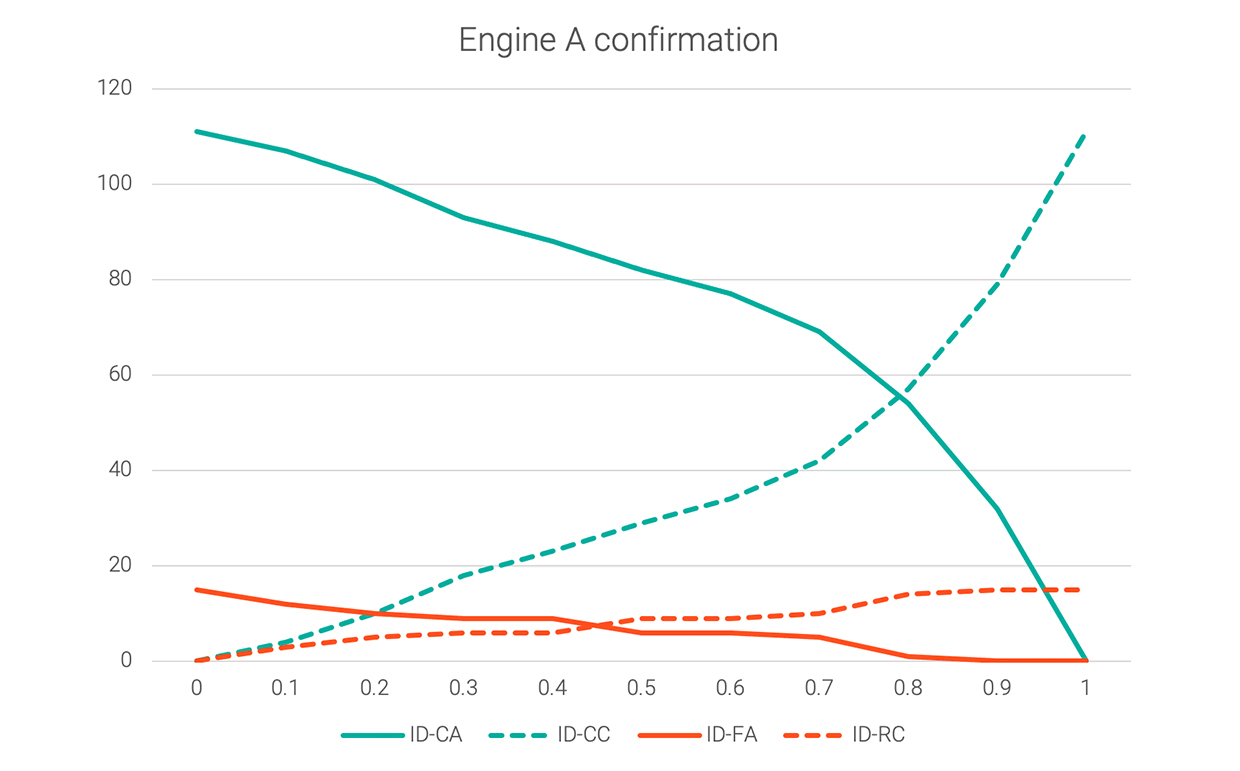
Das Diagramm zeigt, dass bei einem Konfidenzschwellenwert von 0 sowohl „richtig und akzeptiert“ (die optimale Variante) als auch „falsch und akzeptiert“ (die schlechteste) den Maximalwert annehmen. Wenn der Konfidenzschwellenwert auf 0,8 erhöht wird, gibt es fast keine Fehler (falsch und akzeptiert), aber der Benutzer wird in mehr als jedem zweiten Fall um Bestätigung gebeten. Die ideale Einstellung für diesen Schwellenwert liegt bei etwa 0,25. An diesem Punkt ist ID-FA bereits deutlich, ID-CA aber noch nicht zu stark gesunken. Letztendlich kann die Entscheidung anwendungsspezifisch sein: Es ist abzuwägen, wie sich falsche Annahmen im Vergleich zu zusätzlichen Bestätigungsnachfragen auswirken.
Die folgenden Hypothesenkategorien sind relevant für die Entscheidung über den Schwellenwert, wenn jede Hypothese unterhalb des Schwellenwerts abgelehnt wird:
Von diesen Hypothesengruppen sind 1 und 3 richtig; 2 und 4 sind falsch. Das folgende Diagramm zeigt diese vier Werte für denselben Datensatz.
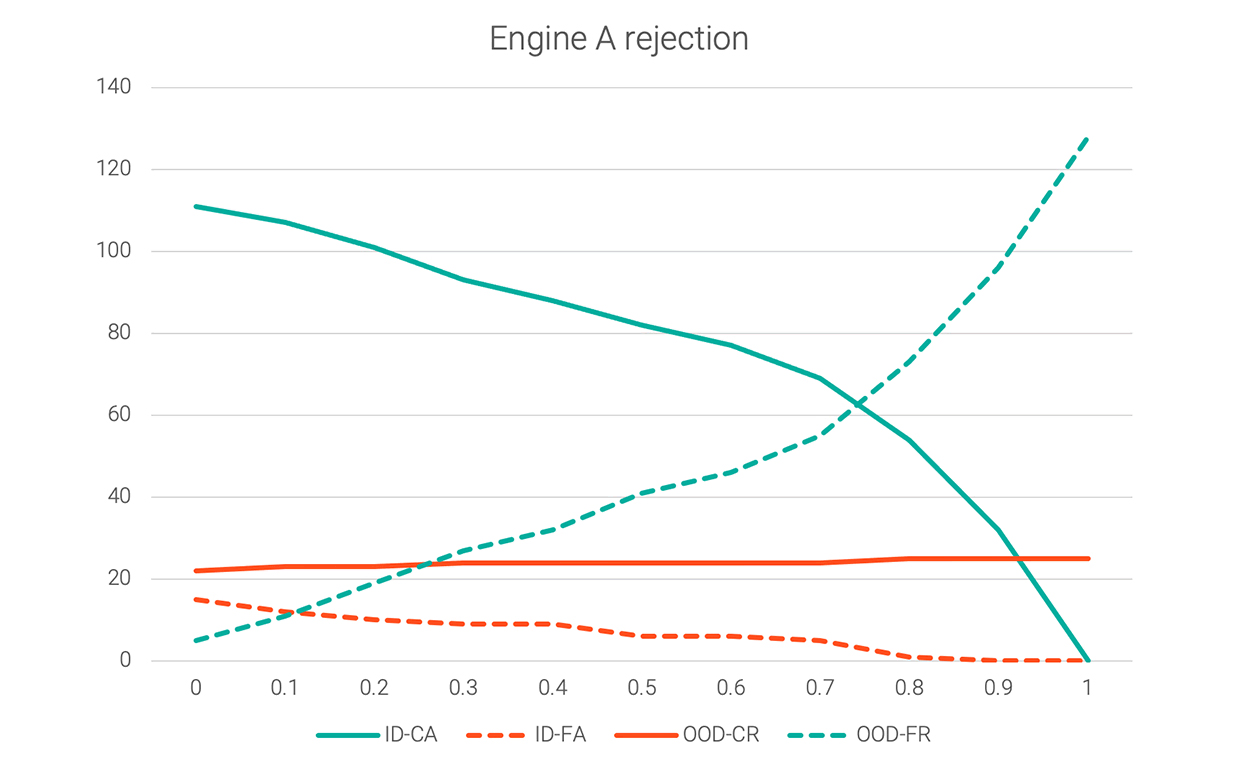
Bei einem Ablehnungsschwellenwert von 0 werden sowohl „richtig und akzeptiert“ als auch „falsch und akzeptiert“ maximiert, „richtig und abgelehnt“ und „falsch und abgelehnt“ dagegen minimiert. Eine Erhöhung des Ablehnungsschwellenwerts auf 0,1 oder 0,2 würde „falsch und akzeptiert“ reduzieren, während „richtig und akzeptiert“ noch nicht steil abgefallen wäre.
Engines für dialogorientierte KI berechnen den Konfidenzwert auf unterschiedliche Weise. Bei manchen Engines (zum Beispiel Engine A) liegen die Konfidenzwerte relativ gleichmäßig verteilt zwischen 0 und 1. Bei anderen sind sie in einem bestimmten Bereich konzentriert – dadurch verändert sich die Form ihres Schwellenwertgraphen. Das folgende Diagramm zeigt den Ablehnungsschwellenwert für eine andere Engine.
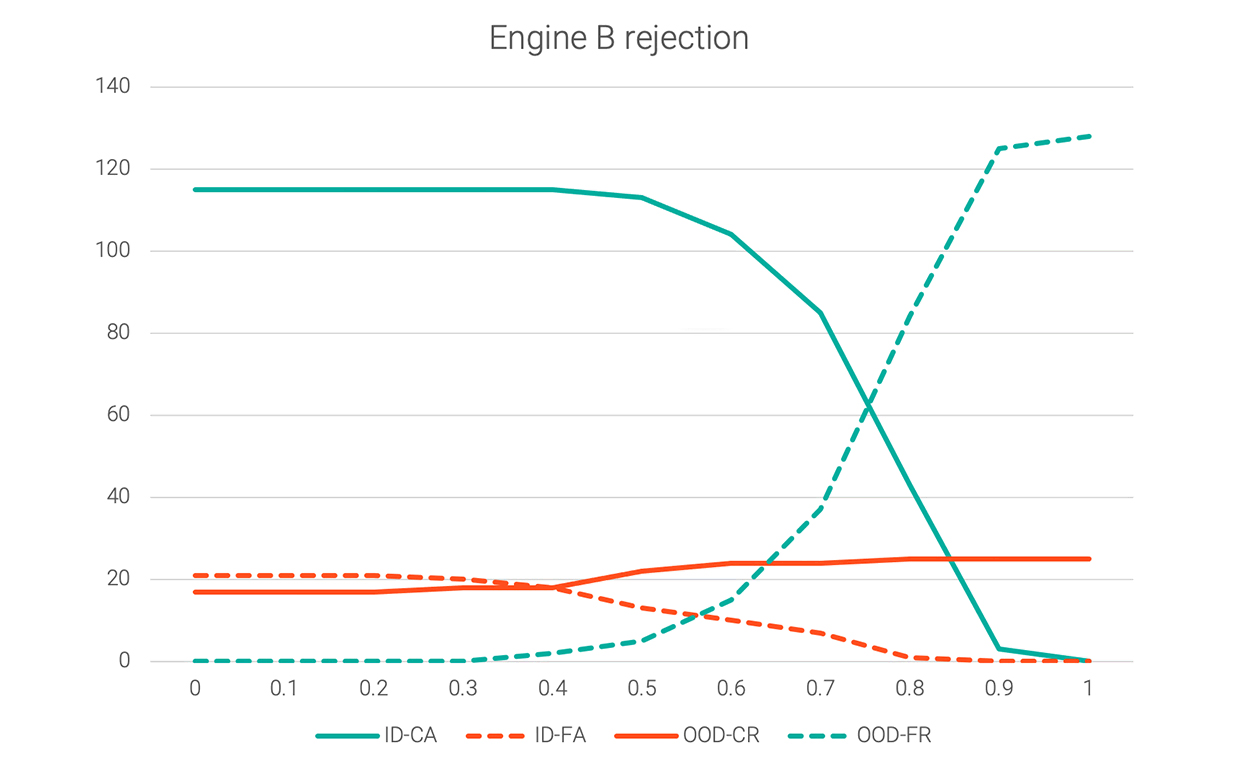
Der Ablehnungsschwellenwert von Engine A (0,2) eignet sich offensichtlich nicht für Engine B, weil bei Engine B die falschen positiven Werte (ID-FA) an diesem Punkt noch recht hoch sind. In diesem Fall wäre 0,6 ein geeigneter Ablehnungsschwellenwert, bei dem ID-FA niedriger liegt, ohne dass zu viel ID-CA verloren geht. Zum Vergleich haben wir in der folgenden Abbildung beide Diagramme übereinandergelegt.
Werden an einer Engine für dialogorientierte KI Änderungen vorgenommen, so kann sich dies auf die Verteilung der Konfidenzwerte für verschiedene Testfälle auswirken. Daher sollten Sie gegebenenfalls den oben beschriebenen Konfidenztest wiederholen, um herauszufinden, ob Sie die Konfidenzschwellenwerte anpassen müssen.
Manche Bot-Frameworks sind für verschiedene NLU-Engines ausgelegt. Das lässt einen Wechsel der Engine trügerisch leicht erscheinen. Prüfen Sie Ihre Konfidenzschwellenwerte, bevor Sie die Engine wechseln. Die optimale Leistung erzielen Sie, wenn Sie auch nach der Erstellung eines neuen Bots die Konfidenzschwellenwerte testen – selbst dann, wenn die NLU-Engine nicht gewechselt wurde. Bei verschiedenen Bots mit derselben Engine kann der optimale Schwellenwert unterschiedlich hoch sein. Lesen Sie den „Praxisleitfaden zum Einsatz von Bots“, um mehr über Best Practices für die Bot-Entwicklung zu erfahren und zu verhindern, dass Fehlinterpretationen von Bots Ihre Kunden in die Irre führen.
 Rahul Garg
Rahul Garg
Rahul joined Genesys in 2021 as Vice President of Product for AI and Self-Service. He leads the development of cutting-edge AI products for Genesys Cloud, including next-generation platforms that harness...
Abonnieren Sie unseren kostenlosen Newsletter und erhalten Sie alle Updates zum Genesys-Blog bequem in Ihre E-Mail-Inbox.


