Your Genesys Blog Subscription has been confirmed!
Please add genesys@email.genesys.com to your safe sender list to ensure you receive the weekly blog notifications.
Subscribe to our free newsletter and get blog updates in your inbox
Don't Show This Again.

In the first blog in the series “In Data we Trust,” we talked about the motivation for data in conversational AI. We also described why Genesys decided to embark on a data collection exercise, and our goals for the project.
In this blog, we lay out the first part of the plan for the data collection exercise, in particular, around understanding the complexities. My hope is that this can be used as a template by Genesys customers, partners as well as research teams across the industry.
Define the Problem Statement
For Genesys, our statement was, “We need a conversational AI dataset that is real, exhaustive and industry-specific. This is so that we can use it to benchmark bot success metrics now, as well as in the future.”
Understand Real-Life Interaction Complexities
The success of a conversational AI data-collection exercise depends on how closely the captured interactions compare to real life. Consider a customer who interacts with a bot on a business’ website. How that customer interacts with the bot depends on multiple factors:
1. Familiarity with the bot – The customer clicks on the chat window and finds out that the “person” on the other side is a bot. That customer will behave differently if they have previously interacted with the bot on the same website.
2. Clarity of the situation – Some customers know the exact issue at hand and have a fair idea of how it will be resolved. At other times, there’s no clarity on what must be done — or even what the problem is. Either way, customers expect representatives to work with them to understand the problem and help resolve it.
3. The voice factor – Voice adds another layer of complexity to an interaction. Customers call into a call center and figure out answers to their questions mid-conversation. Compare that to a chat (text) conversation. A customer types in information only after knowing what they want to convey. Furthermore, voice conversations need to be transcribed for a bot to understand them. That’s an additional source of errors.
4. Presenting the problem – Customers describe their problems based on their understanding of the situation — not how the company’s business processes are defined. For example, a customer might want to open a bank account. But the related business use case is that the customer must be sent to the closest bank branch.
5. The imperfect bot – Bot interactions vary based on how a customer interacts with the bot, and how the bot responds to the customer. Bot authoring is a skill that’s honed. It’s built on the experience of bot development, understanding users and understanding business use cases. In the first few iterations of conversational AI and bot authoring, don’t expect the modeling of the bot to be perfect. A good bot is the result of an iterative process.
Simulate Real-Life Interaction Complexities
A data-collection exercise should consider these complexities of real-life interactions between a customer and a bot. To capture the variability in the interactions and language that’s used requires simulating conditions. This ensures that real-life situations are fairly represented. It’s impossible to collect data that represents exactly how a customer and a business bot would interact. But there are some ways these interactions can get us closer to real life.
A human-to-bot conversation: Quite often, human-to-human conversational datasets are used to postulate bot performance, bot behavior and the user response to bot behavior. Users today interact differently with a human than with a bot. This occurs for a few reasons: It’s not necessary to greet a bot, the perceived benefit of not using full sentences to interact with a bot, and more. For example, a human-to-human conversation might go like this:
“Hi Jenny, I wanted to know when the money that my father sent will be posted to my bank account. He sent it yesterday and I need it urgently to pay my college fees.”
Now here’s the same situation, but with the conversation occurring between a human and a bot:
“Check balance fund transfer yesterday.”
It’s important that the dataset we collect for benchmarking is that of a human-to-bot interaction.
Keeping it real: If users already know what to say — from text they read — it’s not a true test of a real-life human-to-voicebot interaction. Similarly, giving keywords to participants while collecting datasets will bias them as they interact with the chatbot.
To simulate a mixture of the situations that introduce complexities in conversational AI, we presented simulated scenarios. The scenarios provide an event or an incident to the participant. And they’re designed in such a way that a fair inference can be drawn from the situation on what is the presenting use case. For example, instead of asking the participant to “exchange foreign currency,” we presented a scenario of an impending vacation that warranted the exchange of foreign currency.
To understand the role that familiarity plays in bot conversations, we also repeated 20% of the scenarios presented to the user.
When we modeled the intents, we kept the beginner bot author in mind. To simulate this user, we intentionally introduced “confusability” in the bot by adding semantically similar intents. So, what should’ve been just one intent was split into four separate reasonably confusing intents, as shown below.
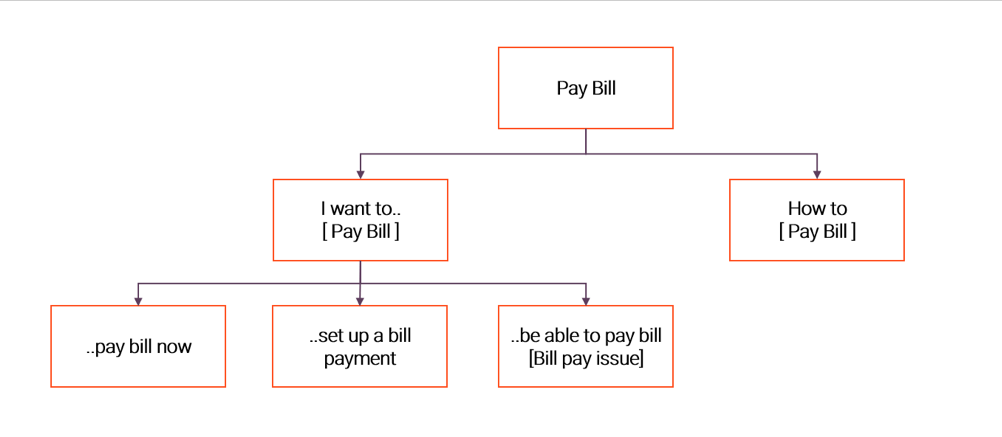
Building an Effective Bot
In Part 2 of this blog, I’ll share with you how we actually use this knowledge to build effective business bots. You’ll also see how this data-collection exercise will help you understand the different types of metrics that are important to your business in defining what’s success and what’s basic improvement.
Get up to speed on the full “In Data We Trust” blog series. Read the first blog, In Data We Trust: AI, Conversational AI and Bots for a grounding in the issues to consider around AI data.
 Harshali Desai
Harshali Desai
Harshali is a Genesys Product Manager in artificial intelligence (AI), with a focus on innovation and research in Conversational AI. She works closely with the AI Applied Research team at...
Subscribe to our free newsletter and get blog updates in your inbox.



