Your Genesys Blog Subscription has been confirmed!
Please add genesys@email.genesys.com to your safe sender list to ensure you receive the weekly blog notifications.
Subscribe to our free newsletter and get blog updates in your inbox
Don't Show This Again.

The Genesys® PureCloud® platform is a native cloud application with a complex ecosystem. The solution consists of more than 200 microservices, deployed in multiple Amazon Web Services (AWS) regions across the globe. Our teams are constantly innovating and improving the PureCloud platform—applying updates to production code several times each day. In fact, last year we released more than 15,000 changes. That means, on average, users can start their daily operations with approximately 42 new changes on the platform each day performed by the PureCloud development teams. Considering AWS also leverages a continuous delivery strategy, users can experience even more changes daily.
Since development on the PureCloud platform began six years ago, we have followed key principles to remain nimble and adapt to our customers’ growing needs:
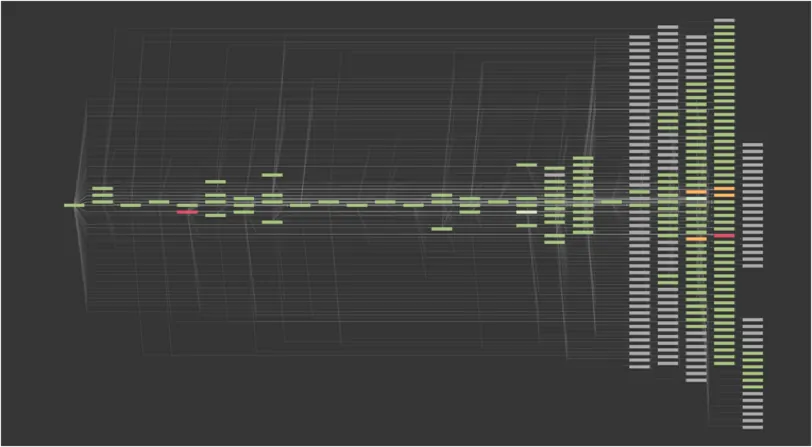
This view below of a single PureCloud deployment demonstrates the complexity of the solution. Each box represents a microservice or data tier; with each microservice or data tier deployed across multiple availability zones. Lines between the boxes represent the communication paths between services and data tiers. Each deployment is contained within a single AWS region.
Preparing for change—and failure
There’s nothing more certain in cloud-native systems than change and failure. In most cases, failure is nothing more than an unanticipated reaction to a change.
Changes can occur in two different forms: intentional and unintentional. Intentional changes are introduced to the system to improve the current state of the system or to introduce additional functionality. Unintentional changes occur because of external factors, such as power outages, changes to the AWS platform, changes in traffic patterns from increased or decreased usage of the service, or cascading failures from an upstream service. We work ceaselessly to anticipate and plan for all possible outcomes before introducing an intentional change into production. PureCloud performs 29,000 automated tests daily in the test environment. Last year, we introduced more than 20,000 intentional changes globally; only three of these code changes resulted in critical incidents due to service delivery.
Planning for unintentional changes is a bit more difficult, and it involves coordination across multiple teams:
How we do it
 Here’s a look at how individual microservices are designed, built and deployed. We like to keep things simple and, as a result, we build small services focused on solving a single problem very well.
Here’s a look at how individual microservices are designed, built and deployed. We like to keep things simple and, as a result, we build small services focused on solving a single problem very well.
Each service is comprised of a load balancer, an autoscaling group with AWS EC-2 instances and a data tier. All services interact with one another through a predefined contract. Each service is required to publish and maintain a contract. And most of our services interact with each other through both synchronous and asynchronous methods.
Understanding immutable systems
One of our primary requirements/principles is to build immutable systems. Adopting this approach means individual components are replaced for each deployment, rather than issuing a hotfix or patch. This allows us to focus on building and managing PureCloud base images, so we can test and validate individual changes before introducing them to production environments. Key advantages:
No binary modifications are made to the original image as it’s tested and promoted through the continuous integration/continuous delivery (CI/CD) pipeline. With immutable and idempotent components, we can easily spin up new instances or replace malfunctioning instances.

Note: All environments have different usage patterns and, as a result, must be tested and validated against an ever-growing and changing set of expectations. The above image provides a quick overview of how usage patterns differ in each environment for a single service. Each environment has a different set of customers; each user/customer has a unique usage pattern.
Observability and transparency for all aspects
To test and validate these conditions, it’s vital to have observability and visibility into production systems. It’s almost impossible to anticipate change or failure in a system if you don’t have the right level of observability and visibility. With good visibility and observability, we can validate and provide confidence that a single change won’t negatively affect the overall system.
We are constantly working to provide observability and visibility into our systems. We want to improve visibility across our teams; in fact, we are dependent on this data
We also leverage monitoring data from production systems for multiple use cases outside of monitoring and alerting. To recreate production workload and usage patterns in lower environments, we use this data to help recreate production issues or incidents in lower environments while predicting and identifying changes in usage patterns.
To simulate a production workload in the lower environment, we have built multiple in-house tools to generate traffic based on pre-defined configurations. We fine-tune testing simulations and configurations based on a weekly review of production metrics and go to great lengths to recreate workload that is identical to production usage patterns. Additionally, we review multiple key metrics, such as requests per minute, latency per request, and ramp-up or ramp-down periods during the day.
Check out the virtual PureCloud tour and experience the platform for yourself.
 Kal Patel
Kal Patel
Kal Patel is the Genesys Principal Architect, SRE for PureCloud. Over the past few years, I have lead teams that create, integrate and evangelize proven technical solutions and best practices....
Subscribe to our free newsletter and get blog updates in your inbox.



